La maggior parte dei sistemi LLM (Large Language Model) commerciali fornisce delle API a pagamento con le quali è possibile realizzare delle applicazioni come chatbot, assistenti virtuali, copiloti, ecc.
L’utilizzo di sistemi commerciali come GPT-4, Bert o Transformer presenta però delle problematiche che ne limitano la possibilità di utilizzo in applicazioni personalizzate ossia applicazioni specializzate e relative ad un dominio specifico:
- Il costo delle interrogazioni cresce con l’aumentare dei dati inviati (quantificato in token) e del numero delle query.
- Il numero di token (quantità di dati inviati) per ogni interrogazione è limitato.
- I dati a disposizione dei LLM non sono aggiornati.
- Se si ha a disposizione un’enorme mole di dati da consultare, relativa a uno specifico dominio e proveniente da fonti di tipo diverso (database, documenti, feed rss, REST API, ecc), non è possibile sfruttarla al meglio.
- E’ necessario inviare al sistema LLM tutti i dati necessari per rispondere a una domanda, anche se sono riservati.
- Le risposte sono soggette ad allucinazioni, soprattutto se le i dati per rispondere a una domanda sono assenti o sono insufficienti.
- Non c’è modo di sapere quali sono le fonti utilizzate per generare una risposta.
E’ nato quindi un modello architetturale chiamato RAG (Retrieval Augmente Generation) [1] [2] che, introducendo delle fasi preliminari all’utilizzo dei LLM, permette di risolvere i problemi citati, in particolare permette di utilizzare i dati aggiornati provenienti da qualsiasi fonte dati e di ridurre il numero delle interrogazioni rivolte al LLM.
L’idea è quella di:
- memorizzare tutti i dati che servono in un database vettoriale,
- estrarre da esso le informazioni che servono per rispondere a una domanda,
- inviare al LLM queste informazioni come contesto della domanda e la domanda stessa in un prompt opportunamente strutturato,
- recuperare ed utilizzare la risposta che il sistema LLM ha generato utilizzando questo prompt.
In questo modo al LLM è richiesta soltanto la produzione di una risposta a partire da un prompt che contiene la domanda e un contesto costituito dallle informazioni recuperate sui propri sistemi.
Funzionamento del dodello RAG
Un RAG è costituito essenzialmente da due componenti: un Retriever e un Generator che svolgono queste funzioni:
RETRIEVER
- Document Loading: Lettura e caricamento dei dati da tutte le fonti disponibili, per fare questo si usano connettori e reader appositi in base alla sorgente dati: database, feed RSS, file PDF, web services, ecc.
- Splitting (Chunking): Divisione dei documenti in unità più piccole e più facilmente gestibili, cercando di fare in modo che siano unità di senso compiuto. Ad ogni chuck è possibile associare dei metadati che permetteranno di risalire alle fonti di una risposta.
- Embedding: I singoli “pezzi di informazione” sono trasformati in vettori di numeri, questa codifica è funzionale al passaggio successivo.
- Storage (Embeddings storage): I vettori numerici, che contengono tutte le informazioni codificate, sono salvate in un database vettoriale, che è un database ottimizzato per gestire dati in formato vettoriale.
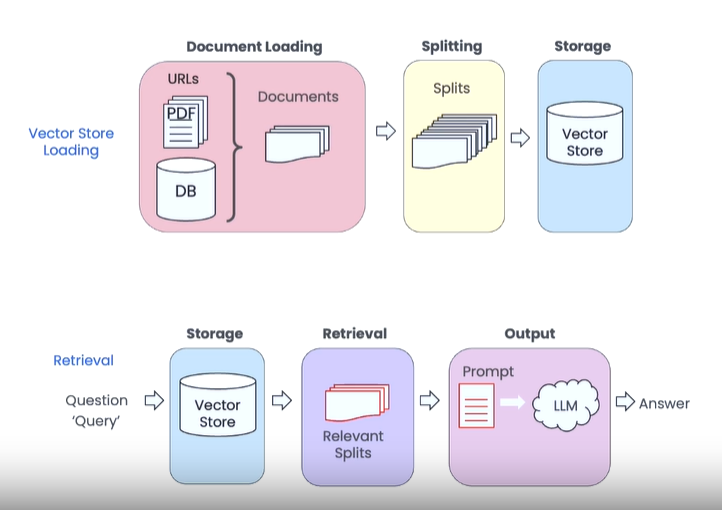
GENERATOR
Nel momento in cui al sistema viene chiesto di rispondere a una domanda (Query), i passaggi sono i seguenti:
- Retrieval: Si invia la Query al database vettoriale il quale la trasforma in un vettore e, dopo una attività di comparazione, restituisce i vettori compatibili, ossia i “pezzi di informazione” che sono rilevanti per rispondere a quella domanda.
- Prompt: Viene preparato un prompt in cui la domanda è la Query dell’utente e il contesto è costituito dai “pezzi di informazione” recuperati nel passo precedente.
- Output generation: Il prompt viene inviato al LLM il quale lo elabora e produce una risposta che è il risultato del processo.
Poiché ad ogni chuck di dati sono associati dei metadati è possibile risalire alle fonti che sono state utilizzate per generare una risposta.
Utilizzando questo sistema è probabile che i dati recuperati nella fase di Retrieval siano tanti e che non possano essere inclusi in un solo prompt. Esistono varie tecniche per affrontare questo scenario che prevedono ulteriori filtraggi di questi dati o richieste molteplici, in sequenza o in parallelo, al LLM. Comunque è meglio affrontare questo argomento in un post specifico.
Framework utilizzabili
Per implementare un sistema RAG si può ricorrere a dei framework e dei sistemi che svolgono le azioni descritte nei paragrafi precedenti:
- Framework RAG:
- LangChain: è un framework open source per lo sviluppo di applicazioni che utilizzano LLM, come chatbot e agenti virtuali, attraverso strumenti e API disponibili in librerie Python e JavaScript. LangChain permette di rappresentare processi complessi sotto forma di componenti modulari. Queste componenti possono poi essere concatenate per realizzare applicazioni più o meno complesse. Gli strumenti principali offerti dal framework sono: Models, Prompt, Parser, Chains, Agents, ecc.
- LLamaIndex: è framework consente di recuperare e strutturare i dati privati o specifici del dominio e di utilizzarli in modo efficiente in applicazioni personalizzate. Offre degli strumenti per: recuperare i dati da varie fonti, indicizzarli e salvarli in database vettoriali, interrogare database vettoriali, preparare prompt strutturati e interrogare LLM.
- Database vettoriali:
-
- Pinecone
- Qdrant
- Milvus
- Weaviate
- ElasticSearch
- Chroma
-
- Large Language Models:
- GPT-4
- Bert
- Transformer
Corsi utili
DeepLearning.AI fornisce una serie di mini-corsi molto interessanti che introducono all’utilizzo dei LLM (per esempio GTP-4) e alla realizzazione di applicazioni RAG (per esempio LangChain, LLmaIndex, ecc).
I corsi sono tenuti spesso dai creatori degli stessi framework e sono coordinati da Andrew Ng che è uno dei massimi esperti di AI e reti neurali, oltre a essere un ottimo divulgatore.
Possibili post di approfondimento da realizzare
Mi piacerebbe prossimamaente approfondire questi argomenti:
- Come eseguire un LLM in locale: Eseguire un modello LLM in locale con Ollama, Come eseguire un modello LLM in locale con LM Studio.
- Una interfaccia grafica per Ollama: OpenWeb UI.
- Realizzazione di un sistema RAG con Open Web UI e Ollama: progetto ChefGino.
- Fine-tuning di un modello vs sistemi RAG.
- Come realizzare un RAG con LlamaIndex.
- Database vettoriali e ChromaDB.
Stay tuned !!!
Fonti e riferimenti
- [1] Retrieval-Augmented Generation for Large Language Models: A Survey – Yunfan Gao, Yun Xiong e altri.
- [2] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks – Patrick Lewis, Ethan Perez e altri.
- [3] A Cheat Sheet and Some Recipes For Building Advanced RAG – Andrei su LlamaIndex Blog.
- [4] High-Level concepts: Retrieval Augmented Generation (RAG) – LlamaIndex documentation.
- [5] LangChain for LLM Application Development – Andrew Ng e Harrison Chase su DeepLearning.ai.
- [6] LangChain Chat with Your Data – Andrew Ng e Harrison Chase su DeepLearning.ai.
- [7] Building and Evaluating Advanced RAG with LlmaIndex – Andrew Ng, Jerry Liu e Anupam Datta su DeepLearning.ai.
- [8] Vector Databases: from Embeddings to Applications – Andrew Ng e Sebastian Witalec su DeepLearning.ai.
- [9] Vector Databases per l’A.I. – HPA su Medium.com.
- [10] RAG: The link between pre-trained language models and real-time data di ZBrain.
- [11] What is the Difference Between LlamaIndex and LangChain di Jeff.
- [12] Short Courses di DeepLearning.AI.
- [13] LangChain – sito ufficiale.
- [14] LlamaIndex – sito ufficiale.